

Dominar a engenharia de prompts para o Google Gemini exige entender como o processamento de linguagem natural (nlp) decodifica a intenção humana. A otimização atual prioriza a densidade semântica e a profundidade contextual em vez de palavras-chave isoladas. Para que o modelo gere respostas com autoridade, seu input deve atuar como um guia estruturado, definindo personas, tarefas e restrições claras.
Neste guia, exploraremos como a interconexão de conceitos e a coerência factual influenciam a lógica do sistema. O uso de termos de indexação semântica latente (lsi) permite criar instruções que o modelo interpreta de forma holística.
Anúncio
Vamos detalhar técnicas para remover ambiguidades e alinhar a sintaxe do comando às capacidades de inferência do Gemini, garantindo resultados que entregam valor e autoridade ao seu conteúdo.
O que é um prompt eficaz para Gemini?
Um prompt eficaz para o Gemini é uma instrução que utiliza diretrizes claras para reduzir a ambiguidade no processamento de linguagem natural (nlp). Em vez de ser apenas uma pergunta genérica, ele funciona como um mapa que situa o modelo dentro de um campo semântico específico, aumentando a relevância dos resultados.
Para construir um prompt desse nível, é preciso considerar alguns pilares técnicos:
- Contexto e lsi: O uso de termos relacionados e palavras-chave do mesmo domínio ajuda o modelo a compreender o tema central. Isso garante que a resposta seja pertinente ao assunto pretendido, utilizando a indexação semântica latente para evitar interpretações erradas.
- Gestão de tokens: Um bom prompt é denso e direto. Ele fornece as informações necessárias sem desperdiçar espaço na janela de contexto, o que mantém o foco do modelo na tarefa principal e melhora a qualidade da inferência.
- Redução de alucinação: Ao definir limites claros e fornecer dados concretos, você minimiza as chances de a inteligência artificial gerar fatos incorretos. A especificidade ajuda o modelo a filtrar o conhecimento e a se manter fiel aos dados fornecidos no input.
- Aprendizado em contexto: Fornecer alguns exemplos de como a resposta deve ser estruturada ajuda o Gemini a reconhecer padrões de sintaxe e tom de voz. Essa técnica permite que o output final siga exatamente o formato desejado, seja ele um código, uma lista ou um texto técnico.
Construa prompts eficazes para o Gemini
| Componente | Função primária | Aplicação prática |
|---|---|---|
| Instrução | Define a ação principal que o modelo deve executar. | “gere um script python para análise de dados.” |
| Contexto | Fornece informações relevantes ou dados de entrada ao modelo. | “considere o arquivo csv anexo, contendo métricas de desempenho.” |
| Formato | Especifica a estrutura e o tipo da resposta esperada. | “a saída deve ser um objeto json validado, com chaves ‘variável’ e ‘valor médio’.” |
Engenharia de Prompt na prática: Modelos otimizados por setor
A teoria da construção de instruções atinge seu potencial máximo na aplicação direta. Utilize estas estruturas testadas para extrair o melhor desempenho do modelo Gemini em diferentes cenários profissionais e acelerar seus resultados.
Design e geração de imagem
Domine como criar prompts de imagem no Gemini focando em descrição técnica granulada. Compreender a lógica do prompt de imagem no Gemini acelera a produção de ativos visuais de alta fidelidade.
Modelo de Prompt: “Atue como fotógrafo publicitário. Descreva uma cena de produto para um relógio de luxo. Especifique iluminação macro, profundidade de campo rasa, texturas metálicas realistas e estilo cinematográfico 8k.”
Marketing digital, vendas e copywriting
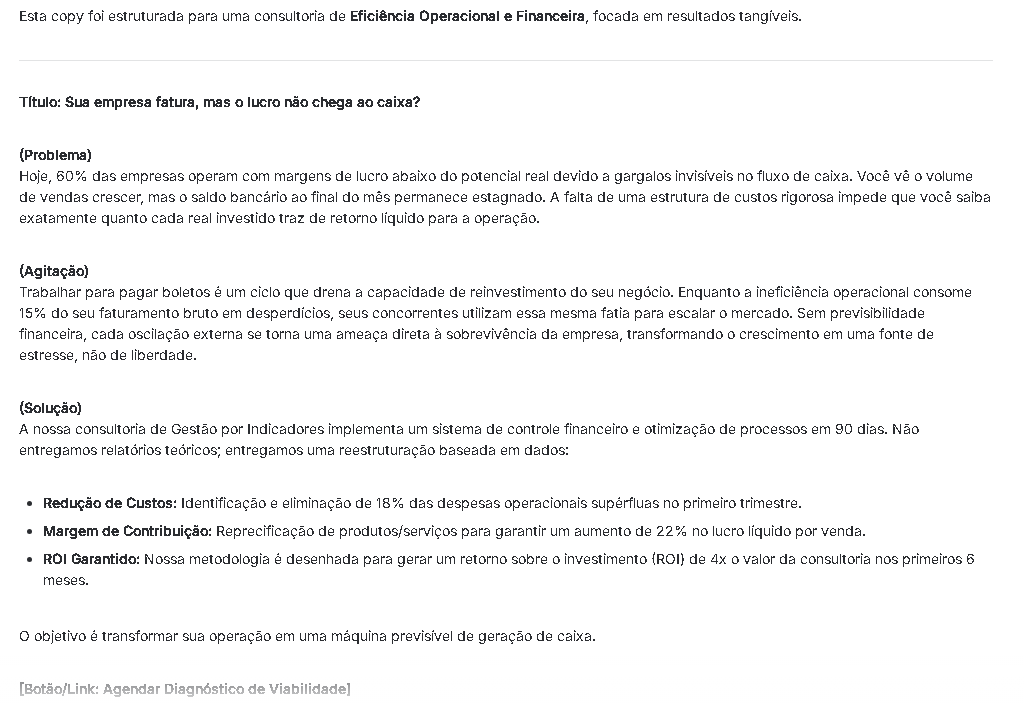
Potencialize seu marketing digital criando anúncios estratégicos. Estruture landing pages de alta conversão e refine seu email marketing para escalar as vendas.
Modelo de Prompt: “Escreva uma copy de vendas para um serviço de consultoria. Utilize o framework PAS (Problema, Agitação, Solução). Elimine adjetivos genéricos. Foque em métricas de ROI e clareza na proposta de valor.”
Carreira e aprendizado de idiomas
Use a inteligência artificial para melhorar o LinkedIn e destacar conquistas profissionais mensuráveis. O modelo auxilia quem deseja aprender inglês através de simulações de conversas avançadas e correções gramaticais em tempo real no processo de estudo de idiomas.
Modelo de Prompt: “Aja como um recrutador executivo. Analise as experiências do meu perfil. Sugira alterações para destacar liderança e gestão de crises. Utilize verbos de ação fortes.”
Setores técnicos, direito e engenharia
Automatize fluxos na construção civil ou utilize prompts prontos para advogados para analisar contratos extensos em busca de riscos jurídicos. Desenvolvedores podem criar sites funcionais ou configurar agentes de IA para tarefas repetitivas.
Modelo de Prompt: “Identifique cláusulas de rescisão abusivas no contrato anexado. Liste os pontos críticos em tópicos diretos. Sugira redações alternativas que protejam os interesses do contratante.”
Entendimento do modelo Gemini e suas capacidades

O desenvolvimento de prompts eficazes para o Google Gemini exige uma compreensão fundamental de sua arquitetura e capacidades. Gemini é um Large Language Model (LLM) multimodal, baseado na arquitetura Transformer, projetado para processar e gerar conteúdo em múltiplos formatos, incluindo texto, imagem, áudio e vídeo.
Sua capacidade de integrar diferentes modalidades de entrada diferencia-o de modelos puramente textuais, permitindo interações mais ricas e complexas.
Arquitetura multimodal e implicações no prompting
A natureza multimodal do Gemini significa que ele não apenas compreende texto, mas também pode analisar e contextualizar informações visuais ou auditivas. Um prompt pode, incluir uma imagem de um gráfico e uma pergunta sobre os dados representados, ou um trecho de áudio para transcrição e análise de sentimento.
Este recurso exige que o engenheiro de prompt considere como diferentes tipos de dados serão estruturados e apresentados ao modelo para otimizar a interpretação e a relevância da saída. A entrada multimodal precisa de uma formatação específica, envolvendo referências a URIs de mídia ou codificações base64.
Capacidades de reasoning e contexto
Gemini exibe capacidades avançadas de reasoning, permitindo-lhe realizar tarefas que vão além da mera recuperação de informações, como resolução de problemas complexos e inferência lógica.
O tamanho da janela de contexto, que varia entre as versões ( 200k tokens para Gemini 3.1 Pro Preview), define a quantidade de informação que o modelo pode processar em uma única interação.
Uma janela de contexto maior facilita prompts mais longos e detalhados, permitindo ao modelo manter um estado conversacional e referenciar informações prévias, mas também aumenta a latência e o custo computacional por inferência.
Tokenização e limites de contexto
A tokenização converte a entrada textual em uma sequência de tokens, que são as unidades mínimas de processamento do modelo. Cada modelo possui um limite máximo de tokens que pode processar em uma única interação, conhecido como janela de contexto.
Exceder este limite resulta no truncamento do prompt ou na incapacidade do modelo de processar a requisição completa. Uma janela de contexto típica para modelos de linguagem pode variar de 8.000 a 1.000.000 tokens, dependendo da versão e da otimização.
Gerenciar o uso de tokens exige concisão e a remoção de informações redundantes. Informações cruciais devem permanecer dentro dos primeiros tokens da sequência, pois a atenção do modelo pode decair em prompts muito longos.
Instruções de sistema e persona
Instruções de sistema, também conhecidas como “system instructions” ou “system prompt”, definem o comportamento geral e a persona do modelo antes da interação do usuário. Este componente molda a saída do Gemini, estabelecendo diretrizes como o tom de voz, o formato de resposta e a função esperada do modelo.
Definir uma persona, como “Você é um especialista em SEO focado em marketing de conteúdo”, direciona as respostas para essa especialidade. A instrução de sistema é persistente ao longo da sessão, influenciando todas as interações subsequentes.
Uma instrução mal formulada ou ambígua pode levar a respostas inconsistentes ou fora do escopo desejado. O posicionamento inicial desta instrução na janela de contexto é essencial para a sua influência máxima.
Estratégias avançadas de engenharia de prompt
A engenharia de prompt vai além da formulação de perguntas diretas, abrangendo técnicas que guiam o modelo através de processos de raciocínio complexos. A escolha da estratégia depende da complexidade da tarefa e da necessidade de demonstrar exemplos ou etapas intermediárias.
Técnicas como few-shot prompting e chain-of-thought permitem extrair raciocínios mais elaborados e precisos. Essas abordagens exploram a capacidade do modelo de aprender com exemplos e de decompor problemas maiores em subtarefas gerenciáveis, resultando em respostas de maior qualidade e relevância.
Few-shot e zero-shot prompting
Zero-shot prompting envolve fornecer uma instrução sem exemplos adicionais, contando apenas com o conhecimento pré-treinado do modelo. É eficaz para tarefas simples ou quando o modelo já possui robusta compreensão do domínio.
Few-shot prompting, por sua vez, inclui exemplos de pares entrada-saída no prompt, demonstrando ao modelo o formato e o estilo de resposta esperados. Esta técnica melhora significativamente a performance em tarefas específicas, como classificação de texto ou tradução com nuances.
O número ideal de exemplos varia conforme a tarefa, mas tipicamente três a cinco exemplos são suficientes para estabelecer o padrão desejado sem consumir excessivos tokens.
Chain-of-thought e raciocínio decomposto
Chain-of-Thought (CoT) prompting instrui o modelo a exibir seus passos de raciocínio intermediários antes de fornecer a resposta final. Esta abordagem melhora a precisão em problemas complexos que exigem lógica multi-etapa, como raciocínio matemático ou resolução de problemas.
Raciocínio decomposto envolve quebrar uma tarefa complexa em uma série de prompts menores e sequenciais, onde a saída de um prompt serve como entrada para o próximo.
Ambas as técnicas aumentam a interpretabilidade do processo de geração e permitem identificar falhas em etapas específicas, facilitando a depuração e o refinamento do prompt. Use CoT para tarefas que se beneficiam de uma explicação explícita do processo.
Ajuste fino de parâmetros de geração
Parâmetros de geração controlam o processo de amostragem da saída do modelo, influenciando a aleatoriedade e a diversidade das respostas. O parâmetro temperature ajusta a aleatoriedade: valores mais baixos (ex: 0.1-0.3) produzem respostas mais determinísticas e focadas, adequadas para tarefas que exigem precisão.
Valores mais altos (ex: 0.7-1.0) geram saídas mais criativas, úteis para brainstorming. Top-p (nucleus sampling) filtra tokens baseados na probabilidade cumulativa, enquanto top-k considera apenas os k tokens mais prováveis.
Ajustar estes parâmetros permite equilibrar a criatividade com a factualidade, otimizando o modelo para requisitos específicos da aplicação, você pode ir ajustando atpe chegar ao nível de respostas que melhor se encaixa ao seu perfil.
Otimização e validação de prompts

A otimização de prompts não é um processo único, mas um ciclo contínuo de experimentação, avaliação e refinamento. Um prompt inicial raramente produz o resultado ideal em todas as condições. Otimizar um prompt envolve identificar padrões de falha, ajustar as instruções ou o contexto, e reavaliar o desempenho.
Esta fase é crucial para garantir a robustez e a consistência das saídas do modelo em diferentes cenários de uso. A validação sistemática garante que o prompt não apenas funcione, mas o faça de maneira previsível e alinhada aos objetivos.
A falha em otimizar adequadamente pode levar a respostas imprecisas, irrelevantes ou até mesmo prejudiciais, especialmente em aplicações de missão crítica.
Metodologia de teste iterativo
Implemente um ciclo de teste iterativo para refinar prompts. Comece com um conjunto de casos de teste representativos da aplicação final. Analise as saídas do modelo para cada caso, identificando desvios do comportamento desejado.
Revise o prompt com base nessas observações, ajustando instruções, exemplos ou parâmetros. Repita o processo até que a qualidade da saída atinja um limite aceitável.
Documente cada iteração e suas modificações, criando um histórico de desenvolvimento. Ferramentas de versionamento, como Git, são úteis para gerenciar diferentes versões de prompts, permitindo reverter a mudanças ou comparar desempenhos.
Avaliação de robustez e consistência
A robustez de um prompt mede sua capacidade de produzir resultados consistentemente e de alta qualidade mesmo com pequenas variações na entrada ou no estado do modelo. Teste a consistência aplicando o mesmo prompt várias vezes ou com pequenas alterações no texto de entrada.
Avalie se as respostas mantêm a coerência sem alucinações ou desvios significativos. Um prompt robusto minimiza a sensibilidade a ruídos ou ambiguidades nas entradas do usuário, garantindo uma experiência previsível. Em cenários de alta demanda, a inconsistência pode levar a erros operacionais ou à perda de confiança do usuário na aplicação.
Mitigação de viés e alucinações
Modelos de linguagem, incluindo Gemini, podem gerar respostas com viés inerente aos dados de treinamento ou alucinar fatos que não existem. Mitigar esses problemas exige estratégias proativas no prompt. Inclua instruções explícitas para neutralidade, verificação de fatos ou para citar fontes quando aplicável.
Para reduzir alucinações, restrinja o domínio de conhecimento do modelo ou instrua-o a responder “não sei” quando a informação não estiver disponível.
Teste rigorosamente o prompt contra entradas que historicamente provocam viés ou alucinações. O uso de técnicas de prompt como CoT pode também expor o raciocínio enviesado, facilitando a correção.
Uso de prompting negativo e instruções detalhadas
O prompting negativo especifica o que o Gemini NÃO deve fazer ou incluir na resposta. Ex: em vez de apenas pedir “Liste os benefícios”, você pode adicionar “Não inclua riscos ou desvantagens”. Esta técnica refina o escopo da saída, evitando informações irrelevantes.
Adicione instruções detalhadas e explícitas para guiar o modelo através de cada etapa da tarefa, especialmente em processos complexos e que exigem mais processamento de dados.
Divida a tarefa em subtarefas menores e forneça uma instrução clara para cada uma, assegurando que o Gemini siga a lógica desejada. Isso é crucial para manter a consistência e a precisão em respostas complexas.
Qual o próximo nível na otimização do seu prompt para Gemini?
Aplique os princípios de clareza, especificidade e limitação de tokens. Teste variações de prompts, ajustando parâmetros como temperature e top_k. Analise as respostas do Gemini de forma crítica, identificando onde a precisão ou a relevância falham.
Adapte a formulação, adicione ou remova exemplos, e refine as instruções para guiar o modelo a uma saída mais precisa. Este processo iterativo faz diferença real para maximizar a eficácia.
Aprimore continuamente sua abordagem, transformando cada interação em um aprendizado. Concentre-se em identificar padrões nas saídas indesejadas para iterar de forma mais eficiente.
A maestria em prompting surge da experimentação metódica e da análise rigorosa. A compreensão profunda das nuances do modelo eleva significativamente a qualidade das suas interações.



